
FASTQ形式はテキストベースの形式で、DNAなどの塩基配列とそのクオリティスコアを1つのファイルに一緒に保存する際に用いられる。 塩基配列とクオリティスコアは各1文字のASCII文字で表され、これにより塩基とクオリティの対応関係が分かりやすくなっている。この形式はWellcome Trust Sanger Instituteで開発されたもので、FASTA形式のデータにクオリティ情報を追加するためのものであった。しかし今日ではIllumina Genome Analyzerのような次世代シーケンサー等から出力された塩基配列のデータを保存する際のフォーマットとしてデファクトスタンダードとなっている。
形式
FASTQファイル内では、1本の配列は4行で記述される。1行目は文字「@」で始まり、その後ろに配列のIDと、オプションとして説明を記述する。2行目は塩基配列を記述する。3行目には文字「+」を記載する。またその後ろに配列のIDを記載することもある。 4行目には2行目に記述した配列のクオリティ値を記述する。このクオリティ値は2行目の配列と同じ文字数でなければならない。
最小のFASTQファイルは、以下のようなものである:
@SEQ_ID GATTTGGGGTTCAAAGCAGTATCGATCAAATAGTAAATCCATTTGTTCAACTCACAGTTT + !''*((((***+))%%%++)(%%%%).1***-+*''))**55CCF>>>>>>CCCCCCC65
元のSangerのFASTQファイルでは、塩基配列とクオリティ文字列の行の折り返しを許していた(その場合、数行飛びに分割される)。 しかし折り返しありのファイルでは、簡素な実装のプログラムではファイルのパージングの際にクオリティ行頭の「@」や「+」を誤ってID等の目印として認識してしまうものもあり、正確に折り返しに対応しようとすると実装が複雑となるため、折り返しありの形式は避けられることも少なくない。
イルミナの配列IDの形式
イルミナのソフトウェアが出力した配列データでは、IDは以下で紹介するような規則で記述されている。
@HWUSI-EAS100R:6:73:941:1973#0/1
| HWUSI-EAS100R | ユニークな機器名 |
|---|---|
| 6 | フローセル内のレーン番号 |
| 73 | レーン内のタイル番号 |
| 941 | タイル内のクラスターの'x'-座標 |
| 1973 | タイル内のクラスターの'y'-座標 |
| #0 | サンプルがマルチプレックスになっている場合のインデックス番号 (インデックスなしの場合は0) |
| /1 | ペアの番号, /1 または /2 (ペアエンド、メイトペアのリードのみ) |
イルミナパイプラインのversion 1.4からは#0の代わりに#NNNNNNの形式がマルチプレックスのIDに使用されるようになった。なおNNNNNNはマルチプレックスで使用するタグ配列。
Casava 1.8では次のように変更になった:
@EAS139:136:FC706VJ:2:2104:15343:197393 1:Y:18:ATCACG
| EAS139 | ユニークな機器名 |
|---|---|
| 136 | Run ID |
| FC706VJ | フローセルID |
| 2 | フローセル内のレーン番号 |
| 2104 | レーン内のタイル番号 |
| 15343 | タイル内のクラスターの'x'-座標 |
| 197393 | タイル内のクラスターの'y'-座標 |
| 1 | ペアの番号, 1 or 2 (ペアエンド、メイトペアのリードのみ) |
| Y | フィルタで落ちた場合はY (悪いリード), その他はN |
| 18 | コントロールビットが立っていない場合は0、立っている場合は偶数 |
| ATCACG | インデックス配列 |
NCBI Sequence Read Archive
NCBI/EBI のSequence Read ArchiveのFASTQファイルは以下のように付随情報を含んでいることがある。
@SRR001666.1 071112_SLXA-EAS1_s_7:5:1:817:345 length=36 GGGTGATGGCCGCTGCCGATGGCGTCAAATCCCACC +SRR001666.1 071112_SLXA-EAS1_s_7:5:1:817:345 length=36 IIIIIIIIIIIIIIIIIIIIIIIIIIIIII9IG9IC
この例ではNCBIが付与したIDと、元のSolexa/IlluminaのID、そしてリード長が含まれている。
また、NCBIはSolexa/IlluminaのエンコーディングのFASTQデータをサンガー形式のエンコーディングに変換したものを提供している(下記のエンコーディングを参照)。
FASTQ形式のバリエーション
クオリティ
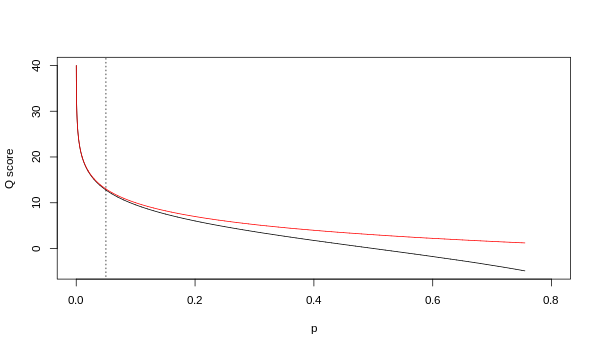
クオリティ値Qは確率pを整数に変換したものである(確率pはそのベースコールが誤りである確率)。よく用いられるのはSangerの式によるスコアで、ベースコールの信頼性の指標として利用されており、このスコアはPhredクオリティスコアとも呼ばれる。

Solexaパイプライン(Illumina Genome Analyzerに付属しているソフトウェア)の初期のバージョン(<version 1.3)ではSangerのスコアとは異なり、以下のようなオッズ比がpの代わりに用いられていた。(version1.3でスコアがPhred(Sanger)スコア対応になり、version 1.8以降はスコア、エンコーディングともSangerと同じになった)

クオリティが高いところでは、これらのスコアはほぼ同じとなっているが、低いところでは違いが見られる(約 p>0.05 またはQ<13)。
エンコーディング
- Sanger形式ではPhredクオリティスコアの0から93の値は、ASCIIコードでは33から126の間の文字としてエンコードされる。(実際のデータではPredクオリティスコアが60を超えることはまれで、ハイスコアが現れるとすればアセンブルされた配列や、マッピング結果中だろう)。このエンコーディングはSAM形式でも採用されている。
- Illumina 1.3+ 形式ではPhredクオリティスコアの 0 から 62 を ASCII の64 から 126でエンコードする。 (しかし実際のReadのデータでは0-40の範囲にPhredスコアは収まる)
- Illumina 1.5+ ではPhredスコアの0から2は少し違った意味を持っていた。0と1は使用されず、2はASCIIの66すなわち「B」としてエンコードされていた。そしてこの2も確率を表すものではなく、 Read Segment Quality Control Indicatorとして使用されていた(一部のReadの末尾に、Readのクオリティスコアが信頼できないので使用しないように、という目印としてBを付けた).